

 Всем, кто работает с электронными таблицами, хоть раз приходилось сталкиваться с задачей удаления дубликатов. Excel для этого предоставляет свои штатные средства, их мы и рассмотрим в этой статье. Сразу скажу, что освещать буду методы простые и безотказные, углубляться в формулы я буду в другой статье - это более тонкая работа.
Всем, кто работает с электронными таблицами, хоть раз приходилось сталкиваться с задачей удаления дубликатов. Excel для этого предоставляет свои штатные средства, их мы и рассмотрим в этой статье. Сразу скажу, что освещать буду методы простые и безотказные, углубляться в формулы я буду в другой статье - это более тонкая работа.
Итак, давайте сначал определимся, что нам нужно. Например, у нас есть таблица данных, где есть совпадения, причем, возможно, по нескольким столбцам. Какие есть задачи:
- Поиск уникальных значений/Поиск дубликатов.
- Получение уникальных значений.
- Получение значений, где есть дублирующие записи.
Метод первый - для Excel 2007 и выше.
Слава богу, для обладателей версии Excel 2007 и выше можно ни о чем не думать. Начиная с этой версии, появилось штатное средство - "Удалить
дубликаты" на вкладке Данные. 
Пользоваться им просто:
- Встаете на вашу таблицу с дубликатами, нажимаете "Удалить дубликаты".
- Появляется окно, где вам нужно выделить те столбцы, по которым у вас могут быть идти совпадения.
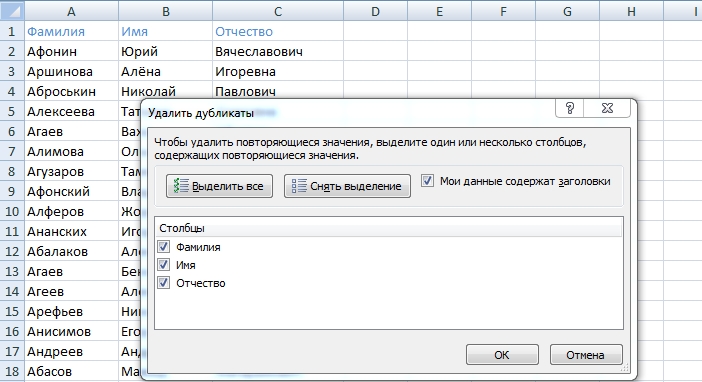 Например, у меня список депутатов Госдумы и некоторые из них повторяются. Я могу выбрать все три столбца Фамилия, Имя и Отчество, а могу просто поискать однофамильцев, тогда я оставлю только первый столбец.
Например, у меня список депутатов Госдумы и некоторые из них повторяются. Я могу выбрать все три столбца Фамилия, Имя и Отчество, а могу просто поискать однофамильцев, тогда я оставлю только первый столбец. - Результатом будет вот такое окно
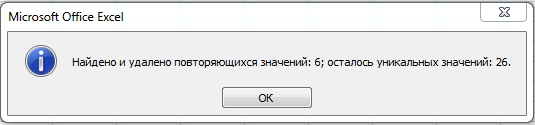
Плюс этого метода - скорость и простота. Надо получить только уникальные значения - решения в два клика, получите и распишитесь.
Минус в том, что если мы более глубоко работаем над таблицей, то мы не сможем понять, какие данные были дублированы (а соответственно, не определим причину дубляжа), а это порой не менее важнее получения нормального списка.
Метод второй - расширенный фильтр.
Этот метод доступен уже и для версии Excel 2003, ниже не проверял, но насколько помню эта версия не сильно прогрессировала по сравнению с 2000й версией.
Этот метод заставит чуть больше повозиться, но и информации можно из него выдоить соответственно. Используется расширенный фильтр. Итак:
- Встаем на таблицу. Нажимаем Дополнительно в группе Сортировка и Фильтр на вкладке Данные
- Появляется окошко, где нам надо выбрать диапазон (который не надо выбирать, если ваша таблица не имеет разрывов и вам нужно удалить дубликаты не по отдельным столбцам) и отметить галочкой пункт "Только уникальные записи". Правда, надо еще определиться, где вы хотите видеть список без дубликатов - на отдельном листе или пусть список отфильтруется на месте. Во втором случае дубликаты не удалятся, а просто скроются, так что можно будет еще с ними поработать. Результат копирования результата в другое место практически аналогичен выше описанному методу с использованием инструмента Удалить дубликаты.
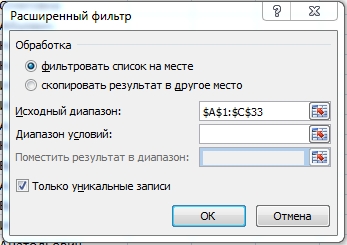
- После этого нажимаете "Ок" и ваши данные отфильтруются или скопируются, в зависимости от того, что вы выбрали. Я буду рассматривать случай фильтрации
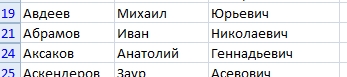 как видите, данные отфильтрованы - это можно видеть по синим номерам строк и нарушенной нумерации (после 19 идет 21, 20я строка скрыта).
как видите, данные отфильтрованы - это можно видеть по синим номерам строк и нарушенной нумерации (после 19 идет 21, 20я строка скрыта). - Теперь уникальные значения можно выделить цветом или забить в отдельном столбце какой-то признак (я ставлю единицу, так проще потом анализировать).

- Теперь выбираем команду "Очистить" и у вас сразу видно, где дубликаты - они или не отмечены никаким цветом либо у них пустые поля. Теперь можно с помощью автофильтра спокойно получить список дубликатов или уникальных значений.
Плюс этого метода в том, что мы имеем выбор - удалять или не удалять дубликаты, а значит, можем работать и анализировать данные.